Статистика как наука
Содержание:
- Средняя скорость движения
- Преимущества
- Дилемма (компромисс) смещения и дисперсии
- 50102 ОКОПФ
- Распределение
- Какую информацию можно получить на сайте?
- Популярное
- Смещение
- Выборка. Объем. Размах
- Служба в России
- Государство
- Меры изменчивости
- Предпринимательство
- Частота
- Информационно-аналитическая работа
- Семплирование
- Мода и медиана
- Заключение
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
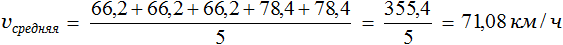
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
66,2 × 3 = 198,6 км.
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
78,4 × 2 = 156,8 км.
Сложим эти расстояния и результат разделим на 5
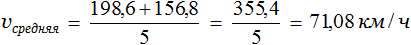
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
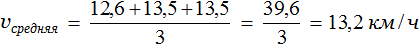
Преимущества
Статотчетность дает возможность бизнесменам делать правильный выбор контрагентов, имеющих высокий уровень рентабельности.
С использованием информации с портала Росстат предприятие может получить сведения о среднем размере заработной платы отдельно по отраслям, о налоговых нагрузках, о сумме максимальных выручек.
Помимо этого, учитывает деятельность предпринимателей, формируя при этом статистические коды.
Они разработаны с целью контроля над деятельностью компаний со стороны органов ИФНС. Наличие кодов необходимы для открытия счета в банке, для участия в тендерах, при проведении аудита.
 Помощь статистических данных в работе предпринимателям
Помощь статистических данных в работе предпринимателям
Дилемма (компромисс) смещения и дисперсии
Смещение и дисперсия вместе составляют итоговую ошибку предсказания модели машинного обучения. В идеальном мире и смещение маленькое, и дисперсия низкая. На практике это связано в дилемму: уменьшение одной из величин неизбежно приводит к росту другой.

Если не вдаваться в детали, обучение модели — это построение функции, график которой лучше всего ложится на точки из тренировочного набора данных.
Модель может нарисовать нам довольно сложную и заковыристую функцию, график, который хорошо охватывает все точки в тренировочных данных. Но если наложить этот график на новые точки (то есть дать функции новые данные), она сработает хуже — так и получается смещение.

Иллюстрация: mofusand
С другой стороны, обучение на разных тренировочных наборах или даже разных датасетах с большой вероятностью даст разброс в предсказаниях, то есть высокую дисперсию.
Более сложные модели дают низкое смещение, но чувствительны к шуму и колебаниям в новых данных, поэтому их предсказания разбросаны. Если при обучении наш снайпер будет учитывать незначимые факторы (вроде цвета мишени или направления магнитного поля Земли), то в другом тире, с другой винтовкой или в другую погоду точность его стрельбы упадёт.
Простые модели, напротив, упускают важные параметры и «бьют кучно, но мимо»
Как другой снайпер, не приученный обращать внимание на ветер и расстояние до мишени
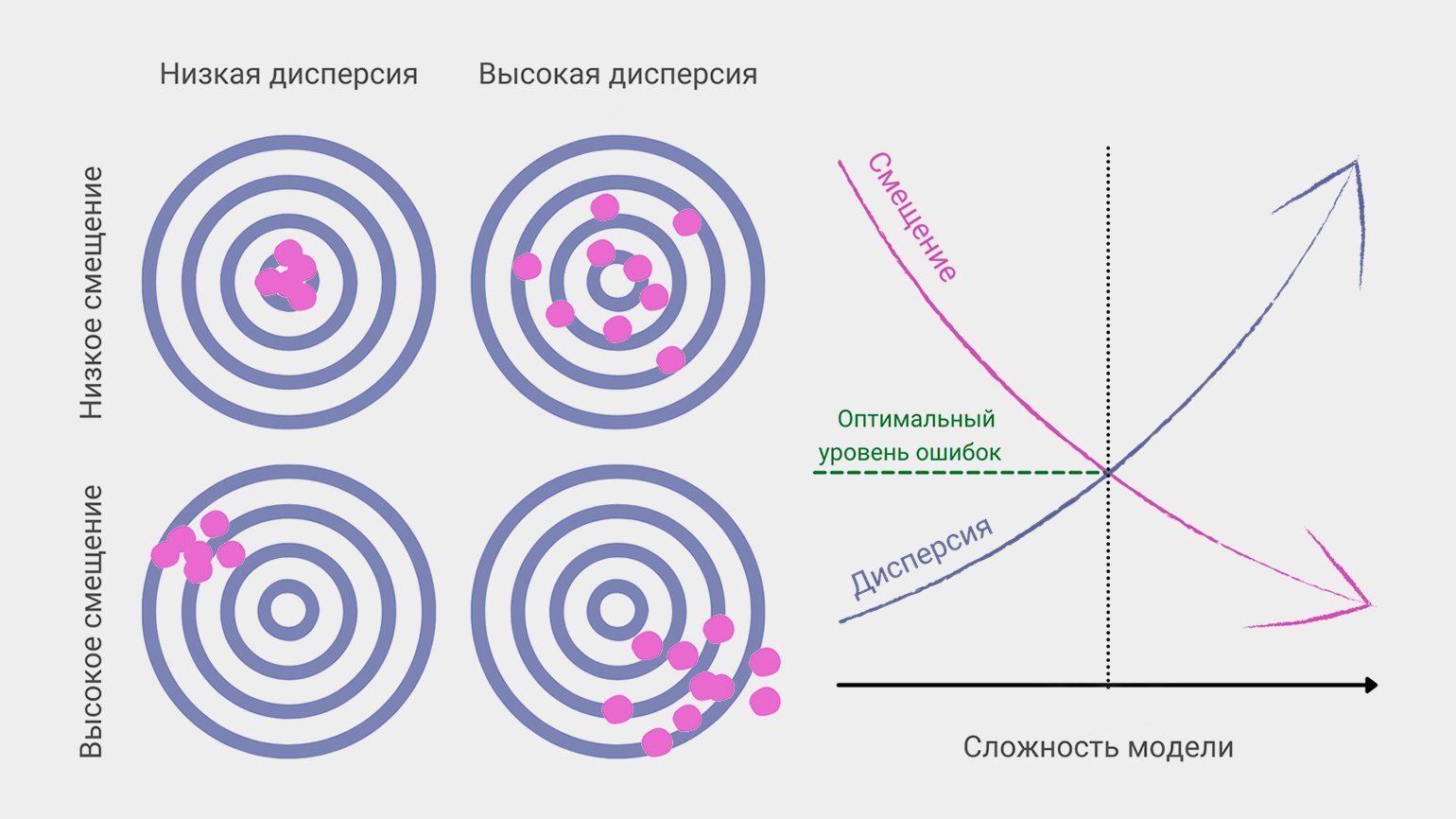
В процессе настройки модели машинного обучения дата-сайентист всегда ищет компромисс между смещением и дисперсией, чтобы уменьшить общую ошибку предсказания.
Кстати, эта дилемма встречается не только в статистике и машинном обучении, но и в обучении людей. В исследовании 2009 года утверждается, что люди используют эвристику «высокое смещение + низкая дисперсия»: мы заблуждаемся, зато очень уверенно.
Учтите это, если захотите сделать свой ИИ более похожим на человека.
50102 ОКОПФ
ОКОПФ представляет собой классификацию установленных и используемых на территории РФ организационно-правовых форм. Расшифровывается ОКОПФ как общероссийский классификатор организационно-правовых форм. При заполнении форм документов в различные органы у ИП возникают вопросы, что означает 50102 ОКОПФ.
Для чего необходим ОКОПФ
Каждый тип организационно-правовой формы подразделяется на отдельные виды, например, организационно-правовые формы для коммерческой деятельности граждан (код 50100) подразделяются на два вида (присваиваются четвертая и пятая цифры кода 01 или 02):
- Первая цифра (от 1-го до 7-и) – правовую форму регистрируемого субъекта. Например, 1 – это юридические коммерческие лица, а 5 – ИП и другие физлица.
- Две последующие – тип организации для каждой из правовых форм первого раздела.
- И в заключении – вид деятельности, так же особенный для каждой формы.
- собирать экономическую статистику по типам хозяйствующих субъектов;
- анализировать социально-экономические процессы в разрезе типа организации;
- разрабатывать рекомендации по налогообложению с учетом данных по обороту для различных форм регистрации предприятий.
Когда надо узнать такой код
Найти код ОКОПФ также можно по юридически оформленной форме субъекта, воспользовавшись общероссийским реестром. Ошибки в кодах статистики могут привести к штрафам за несвоевременное или некорректное предоставление отчетности государственным органам.
Как узнать на сайте Росстата коды статистики по ИНН и получить уведомление онлайн? Информация по кодам находится в свободном доступе, любой желающий может получить ее абсолютно бесплатно. Сведения в базе регулярно обновляются, поэтому предприниматели всегда смогут узнать самую актуальную информацию.
- 1 00 00 — организационно-правовые формы юридических лиц, являющихся коммерческими корпоративными организациями;
- 2 00 00 — организационно-правовые формы юридических лиц, являющихся некоммерческими корпоративными организациями;
- 3 00 00 — организационно-правовые формы организаций, созданных без прав юридического лица;
- 4 00 00 — организационно-правовые формы международных организаций, осуществляющих деятельность на территории Российской Федерации;
- 5 00 00 — организационно-правовые формы для деятельности граждан (физических лиц);
- 6 00 00 — организационно-правовые формы юридических лиц, являющихся коммерческими унитарными организациями;
- 7 00 00 — организационно-правовые формы юридических лиц некоммерческими унитарными организациями.
Росстат — ОКПО по ИНН узнать онлайн
В идеале, эту информацию из Росстата можно узнать в момент регистрации ООО или ИП, но не всегда это делается именно в тот момент. Что именно такое коды статистики, для чего они нужны и, как узнать эти данные стоит рассмотреть немного детальнее.
Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.
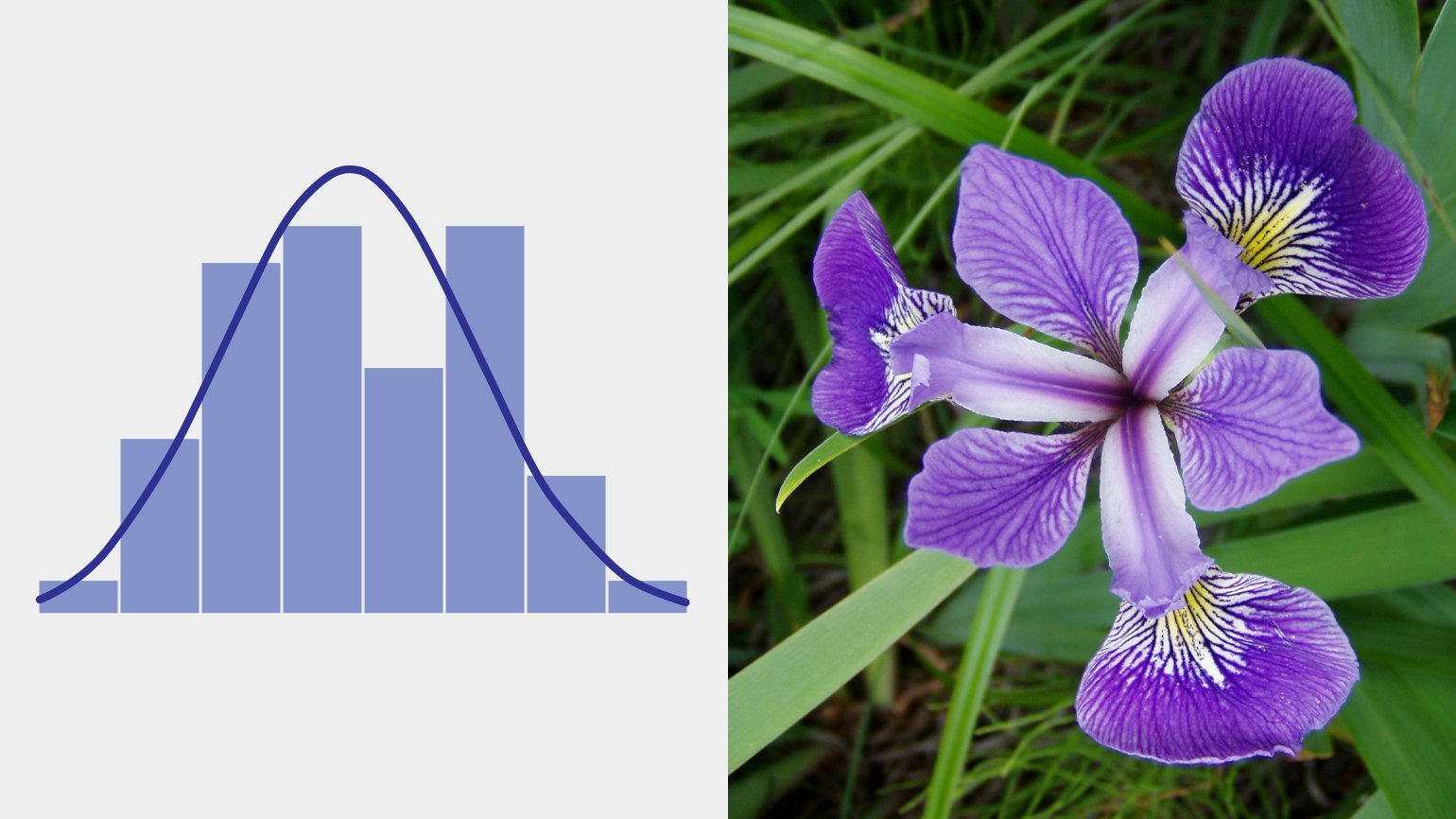
Распределение размеров чашелистика ириса разноцветного. Изображение: Qwfp / Pbroks13 /
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.
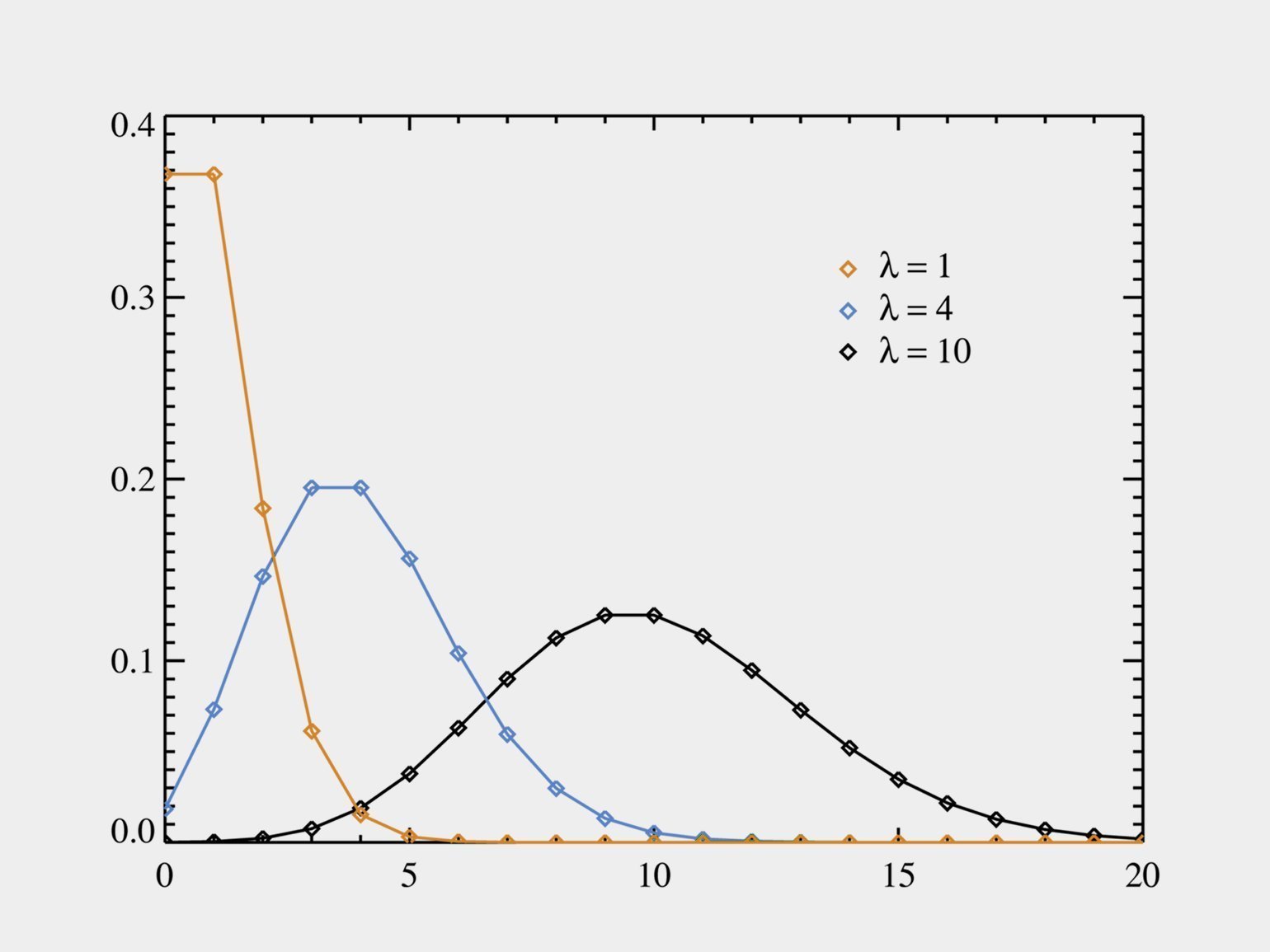
При ƛ = 10 горка Пуассона похожа на колокол Гаусса. Будьте внимательны!
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и , в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
Какую информацию можно получить на сайте?
Помимо информативных сведений на странице имеется много ссылок на интересующие данные в области статистики и по показателям, представленных в виде графической или текстовой информации.
Также в этом разделе имеются ссылки на используемую в работе нормативно-справочную документацию, методологию, на различные интерактивные статистические сервисы.
Для получения исчерпывающей информации о работе Росстата, о его деятельности можно зайти в соответствующий раздел «О Росстате».
Здесь отображены главные задачи и цели компании, информационные материалы о проделанной работе, контактная информация, а также получить недостающую информацию в разделе «часто задаваемые вопросы».
 Блок «Официальная статистика»
Блок «Официальная статистика»
Для аналитиков-маркетологов большой интерес вызывает блок «официальная статистика». В основном он содержит статистическую информацию по показателям макроэкономики.
При нажатии любого раздела осуществляется переход на страницу с официальной статистикой, а при выборе нужного пункта в меню «Содержание» (с правой стороны) выгружается список содержащихся документов и необходимой информации.
Представление данных по статистике может быть отображена в различном виде:
- в таблице;
- в базе данных;
- в кубе;
- в карте.
Каждый вид доступен к просмотру и к выбору для удобства пользования.
 Набор документов и данных в разделе «Официальная статистика»
Набор документов и данных в разделе «Официальная статистика»
Блоки:
- методология – дает пояснения о способах получения данных с методикой их исследования
- оперативная информация – документы, связанные с работой аналитика. В этом блоке отображается последняя обработанная информация;
- официальные публикации – здесь собрана информация, подготовленная сотрудниками Росстата отдельно по каждой теме.
Также здесь можно получить информацию об уровне средней заработной платы в нашей стране, уровне ВВП, а также численности населения.
Передвигаясь по ссылкам можно найти информацию о регламентирующих деятельность Росстата документах, об имеющихся итогах.
Также в этом разделе можно ознакомиться с результатами статистических наблюдений и расчетными материалами, подготовленными службой государственной статистики.
Все рубрики официального портала Росстата доступны к регулярному обновлению актуальной информацией и действующими на данный момент цифрами. Для облегчения восприятия такой информации часть цифровых и некоторых других данных представлены в форме таблицы.
Популярное
Этот раздел предназначен для респондентов и их основной деятельности. Здесь есть формы наблюдения за статистическими изменениями, а также – отчетов в финансах. Для самых организованных пользователей имеется статкалендарь и электронная версия отчетности.
Пункт «Общероссийские и ведомственные Классификаторы» пригодится индивидуальным предпринимателям и организациям с юридическим лицом, так как этим компаниям необходимо иметь доступ к сведениям о шифрах в разных Классификаторах. Цифры оттуда помогут быстрее заполнить необходимые бумаги или подать заявление с актуальными данными.
Смещение
Аналогично тому, как производится выборка из генеральной совокупности, дата-сайентисты из готового датасета выделяют тренировочный набор. Именно на этой «выборке второго порядка» модель учится делать предсказания.
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».
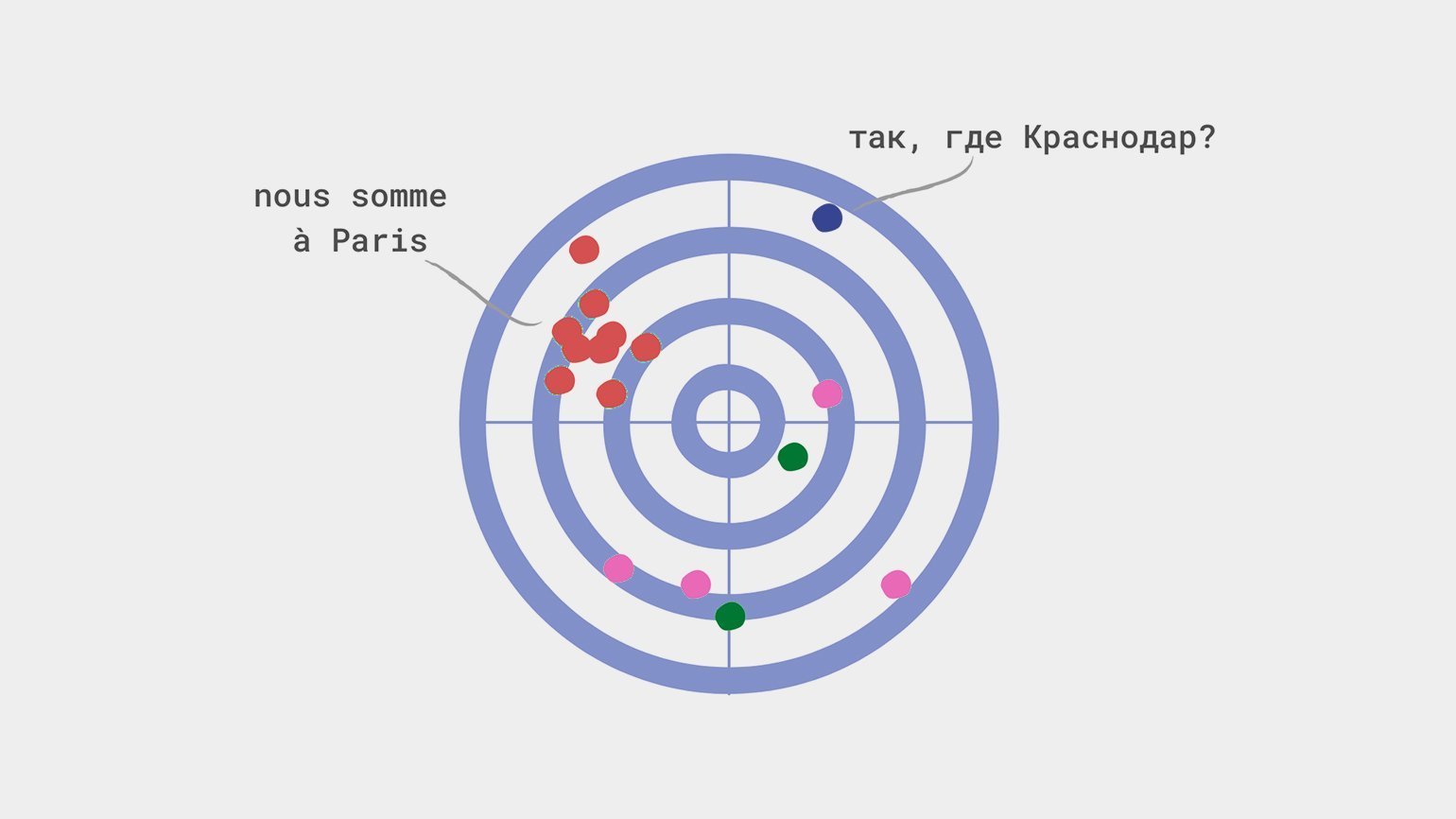
Чаще всего причиной смещения являются:
- неправильный сбор данных в датасет: например, в него попали только краснодарцы — любители Парижа;
- неправильное формирование тренировочного набора из датасета;
- неправильное измерение ошибок.
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.

О доброте дельфинов мы знаем только от спасённых ими людей. Фото: Pixabay
Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
- Эффект низкой/высокой базы. Если в финансовом отчёте найти самый низкий показатель прибыли, то на его фоне любой другой результат будет выглядеть как достижение. И наоборот: если хотите показать, что ученик перестал прогрессировать, сравнивайте текущие оценки с его лучшими результатами за все годы обучения.
- Сокращение рассматриваемого периода. Если хочется доказать, что рекламная кампания не приносит результатов, надо просто найти период, когда деньги уже потрачены, а эффекта ещё нет. И рассматривать только его.
- Исключение из выборки. Если вы измеряете результативность методики снижения веса, то можно выкидывать из выборки участников, которые отказались от методики, не дойдя до конца. Это существенно «повысит» эффективность методики.
- Ну и, конечно же, классика: «Интернет-опрос населения показал, что 100% населения пользуются интернетом».
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
n = 6
Элементы выборки обозначаются с помощью переменных с индексами . Последний элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
В нашем случае, самым большим элементом выборки является элемент 250, а самым маленьким — элемент 150. Разница между ними равна 100
Служба в России
Подразделения есть во всем мире. Наиболее известные – это статкомиссии ООН, ВОЗ, МВФ, Евростат.
Росстат – национальная статистическая служба РФ. День 20 сентября (8 по старому стилю) 1802 г. считается датой образования.
Деятельность его многогранна. Сегодня он обеспечивает официальной информацией всех, от простого россиянина до президента страны. С этой целью регулярно собираются достоверные и объективные сведений во всех сферах – политической, социальной, демографической, экономической и т. д.
Пример! Отрасли с самыми большими зарплатами
В ФСГС сформированы грандиозные информационные ресурсы, базы и банки данных, доступ к которым имеет всякий.
Самые известные, популярные из них:
ЕМИСС – Единая межведомственная информационно-статистическая система, которая связывает воедино официальные учетные фонды разных министерств и ведомств. Из 6 450 показателей 3 431 – Росстата.
Скрин главной страницы сайта fedstat
Интересные цифры! Сколько в России пенсионеров
Статистический регистр – представляет собой ежедневно актуализируемую базу данных о хозяйствующих субъектах, созданных и зарегистрированных в РФ. В нем по каждой организации есть наименование, адрес, виды хозяйственной деятельности, другие регистрационные данные.
Скрин с сайта gks
Росстат обязан обеспечить ведение учета с использованием методов, соответствующих международным стандартам. Иначе нас невозможно было бы сравнить с другими странами мира.
ФСГС выпускает самые разные статистические публикации о социально-экономическом положении государства, федеральных округов, регионов, городов, как комплексные, так и узкоотраслевые.
Территориальные органы обеспечивают конфиденциальность показателей, полученных от предприятий, организаций, предпринимателей, граждан в ходе статнаблюдений, обследований, переписей, их хранение и защиту.
Росстат контролирует, как в стране выполняются законы, касающиеся госстатистики.
Все это – дело рук людей, называемых статистиками.

Фото: работник службы
Примечание! Не нужно их путать со статистами, которых можно встретить в театре или кино, исполняющими незначительные роли без слов.
В Росстате трудятся статистики, а требования к ним предъявляются немалые:
- образование – математическое или финансово-экономическое;
- знание основ экономической статистики, методов анализа показателей работы организаций;
- умение работать с финансовой отчётностью предприятий;
- владение базовыми компьютерными программами.
Государство
При входе на сайт Госстатистики пользователь видит структурированную информацию, вверху экрана есть горизонтально расположенная панель с разделами. Каждый из них подписан, и многие обладают выпадающим списком для удобства – не нужно лишний раз кликать.
Достаточно навести курсор на нужный подпункт и один раз выбрать его для перехода. На текущий момент самыми актуальными темами являются:
- Субъекты РФ, их актуальный перечень, группировка в округа, типы и коды.
- Уровень урбанизации.
- Бюджет России.
- Социальные выплаты.
- Формы и виды собственности.
- Внешний и внутренний долг.
- Инвестиции в основной капитал.
Меры изменчивости
Размах
Размах — это разница между наименьшим и наибольшим числами набора данных. Чтобы вычислить размах, необходимо вычесть наименьшее значение из наибольшего.
Результат показывает, насколько разнообразен набор данных, т.е. насколько он распространен. Но, как и среднее значение, размах очень чувствителен к выбросам.
Дисперсия
Дисперсия измеряет разброс данных. Чтобы вычислить дисперсию, необходимо взять среднюю точку квадратов разностей, полученных из среднего значения.
#1. Найдите среднее значение точек данных
️«Сумма квадратов»
Существует две причины, почему на #3 этапе мы возводим результат в квадрат:
- Отрицательные разницы обладают тем же влиянием, что и положительные, т.е. они не исключают друг друга
- Это усиливает эффект, который есть у выбросов в наборе данных.
️ Полнота данных
На #4 этапе существует небольшое различие, зависимое от того, насколько полным является наш набор данных:
- Для полной совокупности мы делим на количество точек данных (n), т.е. #4 этап был правильным, так как в данном случае мы имеем полную совокупность
- Для выборок мы делим на количество точек данных минус 1 (n — 1)
Среднеквадратическое отклонение
Среднеквадратическое отклонение (обозначаемое греческой буквой «сигма» — σ) — это квадратный корень из дисперсии.
Оно используется для того, чтобы узнать, какая точка данных является выбросом в зависимости от того, на сколько среднеквадратичных отклонений она далека от среднего значения.В нашем случае значение 100 является выбросом:
Перевод статьи Semi KoenStatistics is the Grammar of Data Science — Part 1
Предпринимательство
Это дополнительный раздел, он описывает преимущества, экономические развитие России и стран мира. При ссылке на источник – вы точное знаете откуда были получены данные, что становится убедительным доказательством.
Также здесь проясняется структура: государственная статистика является инструментом для решения поточных вопросов, в ее состав входит Центральный аппарат на Федеральном уровне, плюс территориальные органы Росстата, расположенные по всей стране.
Здесь есть перечень:
- «Конкурсы», где изложены недавние мероприятия, а также размещены извещения о проведении конкурсов в электронном формате.
- Об аукционах – списки текущих и проведенных закупках.
- Ряд незаполненных подзаголовков.
- Приказы о контрактных службах.
- Список членов комиссий, осуществляющих закупки.
- Перечень нормальных документов. Это Приказы Росстата и Федеральные законы.
- Информация о госзакупках, производимых территориальными органами Росстата.
- Статистические данные об осуществлении закупок.
- Контрактные сведения (Росстата с физическими лицами).
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
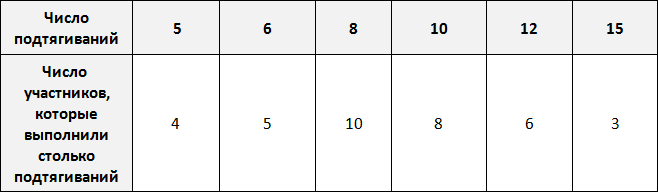
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Информационно-аналитическая работа
Огромную работу проводят территориальные органы Росстата, направляя ее на формирование полной и достоверной информации.
Открытость деятельности Росстата дает возможность различным категориям пользователей получать своевременную статистическую информацию в любой сфере жизнедеятельности нашей страны.
Из года в год, проводя анализы получаемой информации, территориальные органы стараются расширить тематику изданий в области статистики и информационно-аналитических сведений, ставя для себя ориентиры в результате изученных потребностей пользователей.
Для предоставления доступа широкому кругу пользователей к информации статистики социально-экономических процессов, которые происходят в каждом субъекте Российской Федерации, имеют активное использование официальных интернет-порталов территориальных органов статистики.
Многие территориальные органы стараются обеспечивать своевременное размещение на своих интернет-порталах различных информационных и официальных материалов и изданий не только отдельно по региону.
Но по муниципальным образованиям. Благодаря имеющимся разработанным графикам:
- ведется срочная публикация информационных вопросов, имеющих актуальность в настоящее время с содержанием основных показателей развития;
- новостные ленты имеют регулярное пополнение информацией о ведение деятельности, размещение информации о выпусках изданий по статистике;
- поддержание в действующем состоянии рубрики «Муниципальная статистика».
Для знакомства с документами, имеющих регламентирующий характер достаточно зайти в подраздел «Нормативные документы».
 Нормативные документы на официальном сайте Росстата
Нормативные документы на официальном сайте Росстата
Для размещения особенно значимой информации касательно деятельности субъектов экономической деятельности используется единый федеральный реестр.
Здесь формируется юридически значимая информация, связанная с деятельностью:
- юридических и иностранных лиц;
- физических лиц и индивидуальных предпринимателей;
- государственных органов;
- органов местного самоуправления.
Открытость информации предполагает ее представление любому нуждающемуся в ней в свободном доступе всей статистической официальной информации, которая формируется в рамках Федерального плана статработ и официальной статметодолгии.
А также формирование обратной связи с разными категориями граждан (пользователей).
Информационное размещение основных показателей, пресс-релизов, экспресс-информаций, в том числе и отдельных материалов по статистике в области торговли в оперативном режиме на официальных сайтах территориальных органов в условиях информационно-телекоммуникационной сети «Интернет» регулируется приказом Росстата.
Территориальными органами велась работа, направленная на совершенствование представления аналитических данных по вопросам, связанным с внешней торговлей.
Были использованы носители информационных материалов, которые представляются региональными органами таможни.
Основные характеристики показателей по внешнеторговому обороту со странами дальнего и ближнего зарубежья (участники СНГ) включены в сборники, записки и бюллетени.
Можно ознакомиться с динамикой вывоза некоторых видов продукции в Республику Беларусь, а также ввоза некоторых категорий продуктов из Республики Беларусь в регионы России.
Предлагаемый к ознакомлению материал носит сводный характер и в комплексе он готов представить внешнюю торговлю федеральных и региональных округов, с отображением развития международного туризма в субъектах Российской Федерации.
Семплирование
Предположим, вам требуется решить важную задачу: выяснить среднюю ширину морды домашних котов нашей страны. Прямой способ, то есть измерение всех домашних питомцев, невозможен по ряду объективных причин. Придётся ограничиться выборкой — взять какое-то число животных, измерить морды именно им и сделать выводы по итогам только этих исследований.

Иллюстрация: Pixabay
Но тут сразу же возникают вопросы:
- Сколько и каких котов отобрать для замера?
- Почему именно этих, а не других?
- Какие есть гарантии, что вычисленное значение действительно будет средней шириной морды всех котов России?
Семплирование — это группа статистических методов и приёмов, отвечающих на эти вопросы. С помощью семплирования мы формируем нашу выборку так, чтобы она наилучшим образом отражала свойства генеральной совокупности — то есть свойства всех котов страны.

Качественная выборка сохраняет свойства всей генеральной совокупности
Иными словами, вы не можете измерить N первых попавшихся котов и обобщить результат для остальных. Выборка должна хорошо «сидеть» во всей популяции кошек, чтобы можно было делать обоснованные выводы. Такую выборку называют релевантной.
Кстати, статистика и котики — близнецы-братья. После выхода одноимённой книги Владимира Савельева мы говорим «статистика», а подразумеваем «котики», и наоборот. И смело рекомендуем эту книгу всем, кто дочитал до этого места.
В Data Science методы семплирования применяются при разработке, подготовке и оценке датасетов, чтобы они одновременно и были упорядоченными, и соответствовали реальности.
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
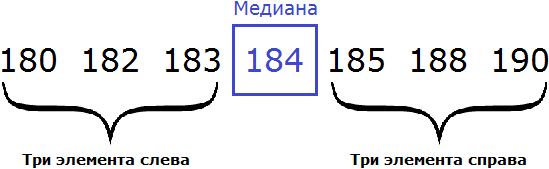
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
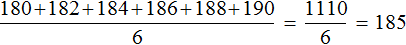
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
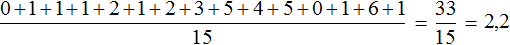
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании
Приходите!